

Classical Consensus
Satoshi was not the first...

On the face of it, gossip and computer science feel fairly separated. Gossip is a ‘sin’ - that your teachers told you to not commit. Computer Science is the tech field - that my parents wanted me to pursue. However, when one digs deeper, gossip can be seen as a complex form of maintaining a societal consensus and academicians have mirrored this behavior in code.

A popular crypto protocol that uses gossip algorithms to propagate event news in the Avalanche network. The efficiency of their particular adaption of gossip is a topic for another day, but the thing to note here is that the basics of gossip - or rather its sophisticated form - consensus can be understood by building up on everyday examples like a Poker game.
In this article, we will move from introducing 2PC to showing its vulnerability to discussing how systems crash and fail. We will then talk about breaking up the end of 2PC into two separate steps to create 3PC which has high availability but can have unsafe runs. Post that we briefly touch upon Paxos and (the famous) Byzantine General’s Problem (BGP) and learn how those protocols make systems more anti-fragile.
Sounds scary and want to stop reading?
I wouldn’t blame you. I spend most of my time on the business side of things in the crypto world, and the tech world is often jargon-laden and it presumes background knowledge. However, in this article, I have worked with Anish (Co-Founder of Panther Protocol and OG Cryptographer) to present a brief primer about consensus protocols that have evolved from the classical distributed systems - in a digestible way. Mostly building up on a game of poker.
Why? Because sometimes it’s important to zoom out and learn from the broader field to maintain diversity in thought. This article might not tell you how to calculate a realistic TAM but it can teach you a) more about the principles of blockchain b) how to build business practices that perform well - even when some ‘nodes’ are behaving in arbitrary ways. Buckle up!
Satoshi Invented Blockchains (x)
The birth of blockchains is often (mis)attributed to Satoshi Nakamoto - the pseudonymous author of the Bitcoin whitepaper. Bitcoin enabled consensus among an open and decentralized set of nodes. However, it was Stuart H and W Scott Stornetta that described a cryptographically secured chain of blocks in their 1990 paper How To Time-Stamp a Digital Document.
They proposed computationally practical procedures for digital time-stamping of such documents so that it is infeasible for a user either to back-date or to forward-date her document, even with the collusion of a time-stamping service. Their procedures maintain complete privacy of the documents themselves and require no record-keeping by the time-stamping service….. Sound familiar?

The genesis of blockchains lies in the field of classical consensus. Since the 1970s academicians like Lamport, Gary, Fischer, Lynch, Paterson, etc have proposed different mechanisms in which databases could come to a consensus and the problems that systems can encounter while doing so.
Initial Work in Consensus Creation
In his 1978 paper titled ‘Time, Clocks and the Ordering of Events in a Distributed System’, Lamport wrote about how messages take a finite time to travel between different nodes.
In distributed systems, with the existence of unique nodes, it is difficult to determine the order of events. A subset of related events, wherein event X caused event Y in some way, are easy to order. However, outside this subset, each observer in a distributed system sees events happen in a different order.

In his paper, Lamport proposed a mechanism that provides a total ordering of events in a distributed network, such that every observer sees events in the same order as every other observer. He also describes distributed state machines (DSMs) that are started in the same state and then have algorithms to ensure that they identically process the same messages. Every machine is now a copy of the other in the network.
The main hurdle is making every machine agree on what is the next message to process: a consensus problem.
What is Consensus?
Consensus protocols detail how to get multiple nodes to agree on a value, that is, (say) if a message should be appended to the blockchain. Having consensus allows distributed systems to act as a single entity with every node aware of and in agreement with the actions of the whole system. Consensus could be achieved on deciding whether or not to append a transaction to a database, electing a leader node to coordinate, synchronizing clocks, etc.

There are two important characteristics of consensus: safety and liveness. In colloquial terms, safety means nothing bad will happen in the system and liveness means that something good will eventually happen. In more technical terms:
Safety/Consistency: if an honest node accepts/rejects a message then all other honest nodes will make the same decision.
Liveness: requests from correct clients are eventually processed.
This article talks about the relationship between safety and liveness in different blockchains. It is a great read to understand the status of protocols in 2018.
Poker Night: Achieving Simple Consensus
Say, Ashoka is trying to arrange a game of poker for four of her friends.

We can identify two steps in Ashoka’s attempt to gain consensus:
Contact every friend, suggest a time, and gather their responses.
If everyone is available at the suggested time, contact every friend again to let them know the game is on.
If everyone is not available at the suggested time, contact every friend again to let them know the game is off.
Mirroring this natural method of consensus, J.N Gary wrote a paper titled ‘Notes on Database Operating Systems’ in 1977. This simple consensus algorithm came to be known as a two-phase commit (2PC). More common versions of methods to gain social consensus involve calculating simple majorities (3 friends are up for Poker on Friday - so the 4th friend can converge to the majority vote) but 45 years ago 2PC was a great fit for the computational power available to researchers at that time.
Two-Phase Commits
Let us formally describe a 2PC’s operations:
The first phase involves proposing a value to every node in the network and collecting responses.
The second phase is a commit/abort phase wherein the results are communicated to the nodes and tells them either to go ahead and commit or abort the process.

Who is the coordinator?
The coordinator proposes values and it does not have to be elected - anyone can act as the coordinator if they want to and initiate a round of two-phase commit.
What are we trying to achieve consensus on?
The consensus here is for acceptance/rejection of the coordinator’s proposed value, not on the value itself. In other words, the nodes are not establishing a consensus about what the value should be, instead, they are agreeing on if they accept/reject the coordinator’s proposed value. In 2PC, the nodes have no mechanism to say ‘let’s vote on x instead of y’ - if they want to vote on y, they will have to initiate a new round of 2PC.
The benefit and problems with 2PC
A two-phase commit provides a low-latency consensus algorithm - the number of messages exchanged for n nodes is 3n. However, as is the problem with most systems, things crash and fail.
Crash and Fails
Nodes can crash in multiple ways. In the ‘fail-stop’ model of distributed systems, a node crashes and never recovers. In the ‘fail-recover’ model, a node crashes and may at some later time recover and continue executing. In Byzantine failures, a node deviates from the protocol rules in completely random ways. The last failure is an active area of research and we shall come back to Byzantine fault tolerance later in the article.
Let us briefly discuss how node failure makes 2PC fragile.
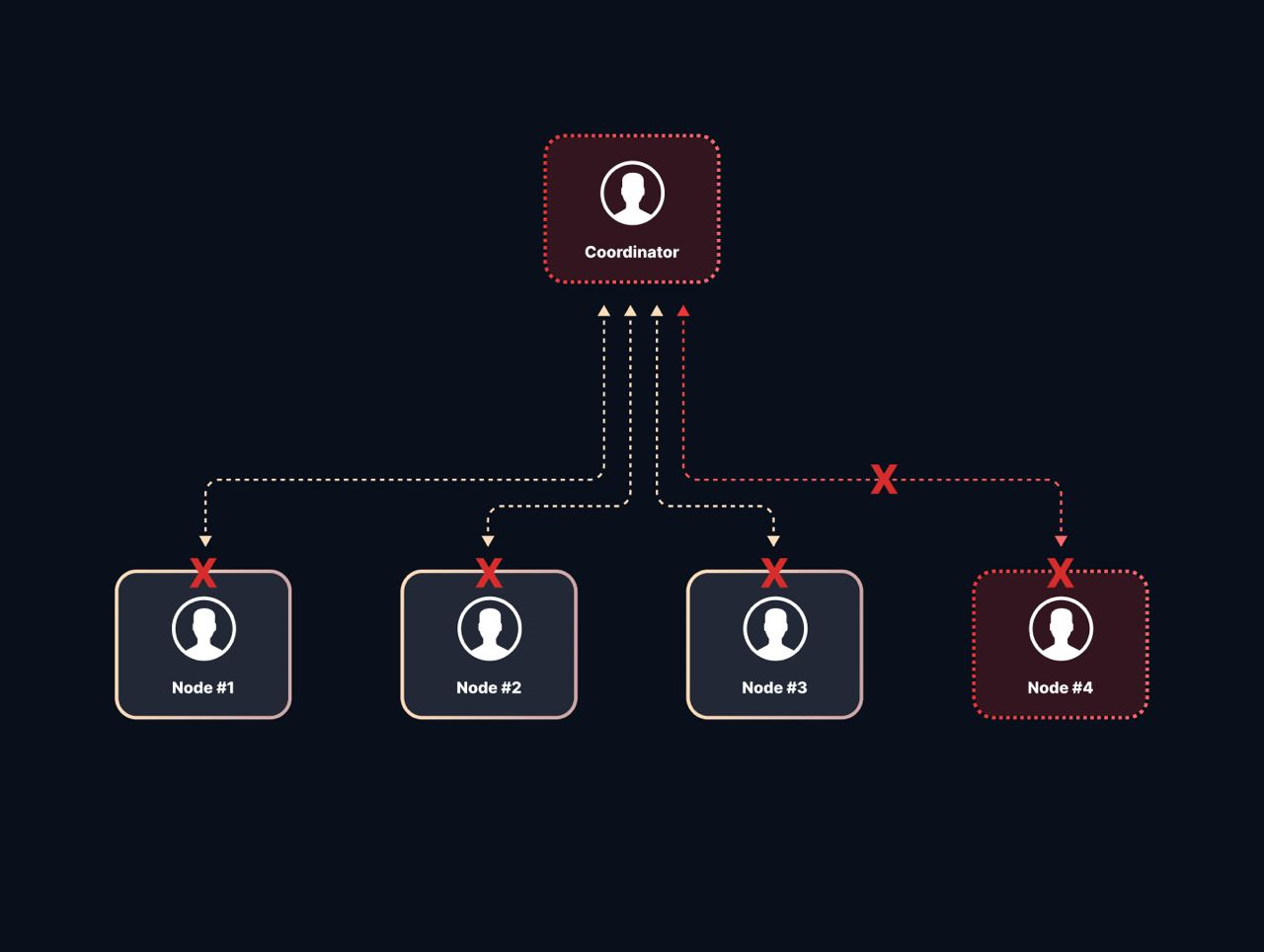
In this consensus algorithm, once the decision to commit has been made, the coordinator communicates the decision to the participants.
The participants go ahead and act upon the commit statement without checking to see if every other node got the message.
However, if a node that committed crashes along with the coordinator, then the system cannot tell what the result of the transaction was because only the coordinator and the node that got the message know for sure.
Since the crashed node might have already committed the transaction, the protocol cannot pessimistically abort - as the transaction might have had side effects that are impossible to undo.
At the same time, the protocol cannot optimistically force the transaction to commit, as the original decision might have been to abort.
The above case will have the network in a hung state. 2PC is safe: no bad data is appended to the blockchain, however, its liveness properties aren’t good - if the coordinator/nodes fail at the wrong point, the network will block.
Three-Phase Commits
About 25 years later, a 3-phase commit algorithm was proposed that avoids blocking problems in 2PC. The second phase of 2PC, the commit phase, is broken into two parts.

Assuming 0 fault tolerance, i.e, the network cannot continue to operate with a single flaw, in the last phase:
If the coordinator receives receipts of ‘prepare to commit’ from all nodes, then the network goes ahead and commits the transaction.
If the coordinator does not receive receipts of ‘prepare to commit’ from all nodes, then the network goes ahead and aborts the transaction.
But what if the coordinator itself crashes?

In that case, 3PC allows a recovery node to take over the transaction and query the state from the remaining nodes.
If any node reports that it had not received ‘prepare to commit’ then the recovery node will abort the transaction, else if the crashed node had committed the transaction then the coordinator must have moved to the commit phase, which means the recovery node can request the live network to commit the transaction.
We very briefly looked at 3PC and even in this mechanism, the network can fork - with different nodes being in different states when the network tries to merge. Thus, 3PC does have unsafe runs, however, it can be used in systems seeking high availability at the cost of low latencies.
Paxos
Eventually, Lamport described the Paxos consensus algorithm in the paper “ The Part-Time Parliament” (submitted in 1990, published in 1998). However, it was a difficult paper to comprehend, and the allegory to Greek parliamentary proceedings did not make it easy for the wider academic community to comprehend this paper. In 2001, Lamport published "Paxos Made Simple” which details that for a given number of fixed nodes, any majority of them must have at least one node in common.
How does it work?
Let us take three nodes X, Y, and Z.
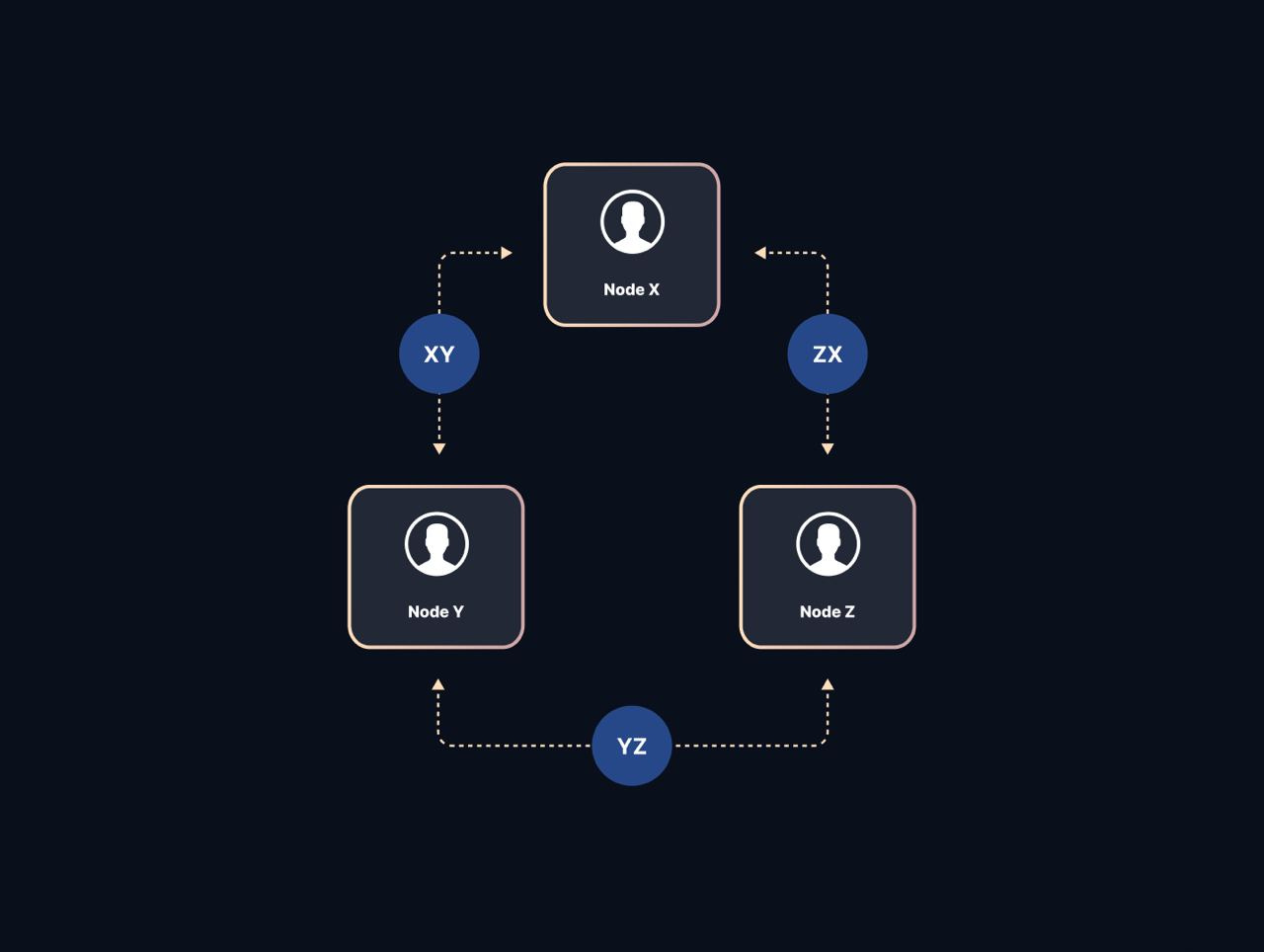
The possible majorities are XY, YZ, and ZX.
If a decision is made when one majority is present (say) XY then at any time in the future when another majority is available at least one of the nodes has the data on what the previous majority decided.
If the majority is XY, then both X and Y will remember.
If XZ is present then X will remember and similarly in YZ majority, Y will remember the decision that was made in the time when XY was in majority.
The pros of Paxos
Paxos can handle lost/delayed/repeated messages and even scenarios when messages are delivered out of order. The network will reach a consensus if there is a single leader for long enough that the leader can talk to a majority of processes twice. Any node, including the leader, can fail and restart and the algorithm is still safe.
Byzantine General’s Problem
We’ve discussed cases in which nodes can crash and fail, but what if they can also behave in completely arbitrary ways? A 1982 paper titled “The Byzantine Generals Problem” walks us through the following scenario:
‘We imagine that several divisions of the Byzantine army are camped outside an enemy city, each division commanded by its general. The generals can communicate with one another only by messenger. After observing the enemy, they must decide upon a common plan of action. However, some of the generals may be traitors, trying to prevent the loyal generals from reaching an agreement.’

Like the warzone or faulty aerospace systems (which is where the main problem statement originated from), distributed networks can often have nodes that send conflicting information to different parts of the network. These nodes may be traitors (malicious) or faulty, under both circumstances, they can actively disturb the consensus of the network.
To tackle this problem academians have designed Byzantine fault-tolerant (BFT) systems that can tolerate failures caused by parts of the system presenting different symptoms to different observers. It must be noted that there is no solution for the BGP for 3n+1 generals with more than n traitors, that is, a system must at least have more than 2/3rd of honest nodes. Blockchains being naturally distributed systems commonly use proof of work, proof of stake, or delegated proof of stake to be BFT systems.
Pit-stop
The field of classical consensus is fairly large and well established. We barely scratched the surface with this article, however, my ambition with this post was to scramble my notes together into a readable blog post. I may or may not return to this topic in the near future.
Then why write a random post?
Because if you poke around the field of consensus long enough - then there are many lessons about nodes crashing and failing to be learned there. Perhaps the answer to having an active DAO lies in a paper that describes how to build a network that has high availability.
Furthermore, the young space of blockchains is already becoming siloed - with people ‘specializing’ in deFi or NFT or infra or tech. However, increased specialization leads to publications that cater only to a very small group of people and inhibit creativity. Hence my attempt to develop breadth - both for myself and you, my dear anon.
Happy Sunday!
PS: Feel free to reach out to me for a list of resources for a deeper dive into classical consensus and please re-direct the tougher questions to Anish (he is the smarter one - by multiple orders of magnitude). Thank you Jaski and Neel for reviewing the article.